
Confronto Qualità Impronte Edifici Italia: 5 Dataset Open Data a Confronto
Se lavori con dati territoriali in Italia — che si tratti di urbanistica, protezione civile, modellazione 3D o analisi immobiliare — prima o poi ti troverai a scegliere il dataset di impronte di edifici più adatto al tuo progetto. Il problema è che oggi esistono almeno cinque fonti principali liberamente scaricabili, ciascuna con filosofia, accuratezza e limiti diversi.
Abbiamo condotto un'analisi quantitativa sistematica confrontando OpenStreetMap, Microsoft Building Footprints, Overture Maps, Google-Microsoft Open Buildings (GBA) e gli Aggregati Strutturali della Protezione Civile (DPC) su 22 aree campione distribuite su tutto il territorio italiano — dalle vie strette del centro storico di Venezia ai casali sparsi della campagna umbra.
I risultati, basati su oltre 80.000 impronte analizzate con 18 indicatori diversi, offrono per la prima volta un quadro comparativo completo per chi deve scegliere la fonte più adatta per il contesto italiano.
Le cinque fonti di building footprints analizzate
Prima di entrare nei numeri, è utile capire da dove vengono questi dati e con quale logica sono stati prodotti. Ogni dataset nasce da un approccio fondamentalmente diverso, e questo spiega gran parte delle differenze che vedremo.
| Dataset | Tipo di produzione | Origine dei dati | Licenza | Copertura Italia |
|---|---|---|---|---|
| OpenStreetMap (OSM) | Community-driven, manuale | Volontari, ricalco da catasto e ortofoto | ODbL | Eccellente nelle città, variabile in aree rurali |
| Microsoft Building Footprints | Machine learning automatico | Immagini satellitari ad alta risoluzione | ODbL | Globale, uniforme ma geometrie semplificate |
| Overture Maps | Conflazione multi-sorgente | Principalmente OSM, arricchito con altre fonti | ODbL / CDLA | Simile a OSM, con schema normalizzato |
| GBA (Open Buildings) | Fusione accademica guidata dalla qualità | OSM + Microsoft, filtrato | ODbL | Buona, meno densa di OSM per via del filtraggio |
| DPC Aggregati Strutturali | Rilevazione istituzionale | Protezione Civile, finalità rischio sismico | CC-BY-4.0 | Aree urbane principali, non capillare |
OSM è il dataset con la storia più lunga e la semantica più ricca: molti edifici hanno attributi come il tipo (residenziale, commerciale, industriale), il nome, il numero di piani e persino l'anno di costruzione. In Italia la qualità è particolarmente alta perché molti contributori hanno ricalcato le mappe catastali dell'Agenzia delle Entrate.
Microsoft ha adottato un approccio radicalmente diverso: reti neurali addestrate su immagini aeree che estraggono automaticamente le sagome degli edifici. Il risultato è uniforme e globale, ma le geometrie tendono a essere più semplici e l'accuratezza posizionale inferiore rispetto al ricalco manuale.
Overture Maps è il progetto più recente: conflaziona OSM con altre fonti, assegnando ID stabili e uno schema dati normalizzato. Per l'Italia, il contenuto è sostanzialmente OSM con qualche integrazione.
GBA (Open Buildings) è una fusione accademica tra OSM e Microsoft, con un filtraggio guidato dalla qualità che rimuove i duplicati e le geometrie meno affidabili. Include anche altezze LoD1 derivate da un dataset separato.
Gli Aggregati Strutturali della Protezione Civile (DPC) sono un caso a parte: non rappresentano singoli edifici ma gruppi di edifici adiacenti con continuità strutturale, pensati per la classificazione del rischio sismico. Il confronto con le altre fonti è quindi strutturalmente asimmetrico, ma la copertura spaziale resta un dato prezioso.
Metodologia: come abbiamo condotto l'analisi
22 aree campione su 5 tipologie urbane
Per ottenere risultati rappresentativi della varietà italiana, abbiamo selezionato 22 bounding-box di circa 0,01° × 0,01° (~1,2 km²) che coprono cinque tipologie urbane:
- Centro storico denso (7 aree): Roma Centro, Firenze, Venezia, Napoli Centro, Genova, Bari, Padova — tessuto urbano compatto, vie strette, cortili interni
- Grande città moderna (3 aree): Milano, Torino, Bologna — grandi isolati, edifici regolari, aree industriali riconvertite
- Media città (5 aree): Verona, Perugia, Cagliari, Catania, Palermo — mix di centro storico e espansione moderna
- Suburbano (3 aree): Roma EUR, Milano Bovisa, Torino Mirafiori — edilizia residenziale post-bellica, capannoni
- Rurale (4 aree): Toscana, Umbria, Puglia, Sardegna — case sparse, casali, edifici agricoli
Di queste 22 aree, 17 hanno tutte e cinque le fonti disponibili e sono usate per i confronti diretti. Le restanti 5 mancano di almeno una fonte (Cagliari, Catania e Palermo non hanno GBA; Perugia e Cagliari non hanno OSM completo; la Sardegna rurale non ha DPC).
OSM come riferimento primario
Per confrontare i dataset serve un riferimento. Abbiamo scelto OSM, che in Italia ha la migliore combinazione di copertura e accuratezza posizionale — merito della comunità di mappatori e del frequente ricalco dalla cartografia catastale.
Questo introduce un bias importante: le metriche che presentiamo misurano l'accordo con OSM, non la correttezza assoluta. Un edificio reale presente in Microsoft ma non mappato in OSM risulterà un "falso positivo" — anche se è un edificio vero. Teniamo presente questo caveat nell'interpretazione dei risultati.
Matching greedy con ordinamento globale
Per determinare quali impronte nei diversi dataset corrispondono allo stesso edificio, abbiamo implementato un algoritmo di matching basato sull'Intersection over Union (IoU) con soglia ≥ 0,3.
L'approccio è un greedy globale: raccogliamo tutte le coppie (riferimento, test) con IoU sopra soglia, le ordiniamo per IoU decrescente e le assegniamo una sola volta. Questo è più robusto del matching per-riferimento nelle aree dense, dove più edifici di riferimento possono competere per la stessa impronta test.
Pre-elaborazione: esclusione degli edifici di bordo
Ogni bounding-box taglia inevitabilmente alcuni edifici al confine. Queste impronte troncate distorcerebbero le statistiche di area, compattezza e matching. Per questo motivo, tutti gli edifici la cui geometria interseca il confine del bbox vengono rimossi prima dell'analisi. In media, l'esclusione riguarda circa il 7,7% degli edifici — un compromesso accettabile per la pulizia dei dati.
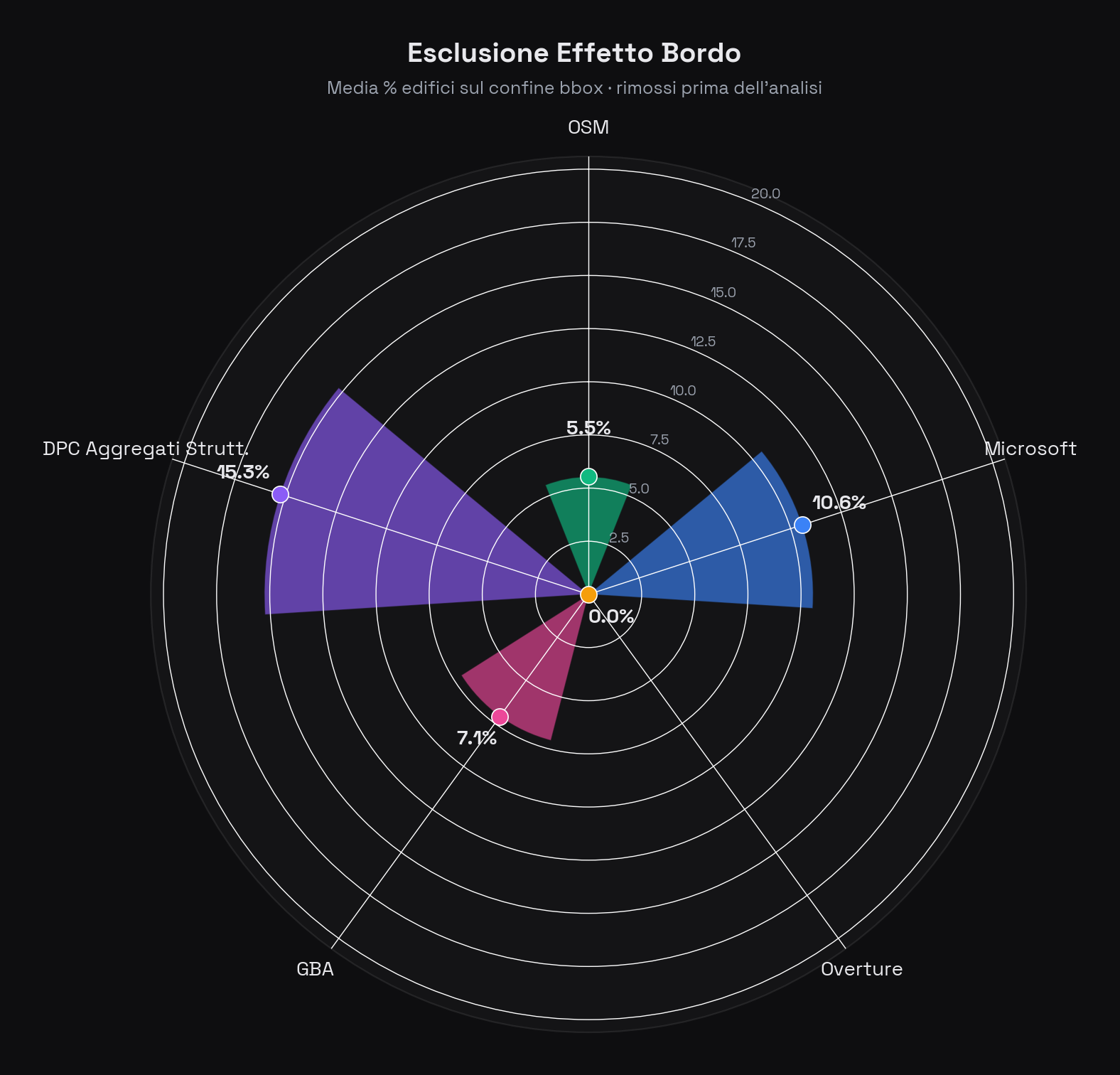
Esclusione effetto bordo per fonte. DPC ha la percentuale più alta (15,3%) a causa degli aggregati strutturali che sono geometrie di dimensioni maggiori e intersecano più spesso i confini. Overture ha un valore quasi nullo perché le sue impronte sono già clippate.
Proiezione e misurazioni
Tutti i calcoli metrici usano EPSG:32632 (UTM zona 32N), il sistema di riferimento standard per l'Italia continentale. Per Sicilia e Sardegna, UTM 33N sarebbe più preciso, ma la distorsione risultante a queste latitudini è di circa 2 cm/km — trascurabile per le nostre analisi.
Quanti edifici rileva ciascun dataset?
La prima domanda che chiunque si pone è: quanti edifici trovo? La risposta varia enormemente a seconda della fonte e del contesto urbano.
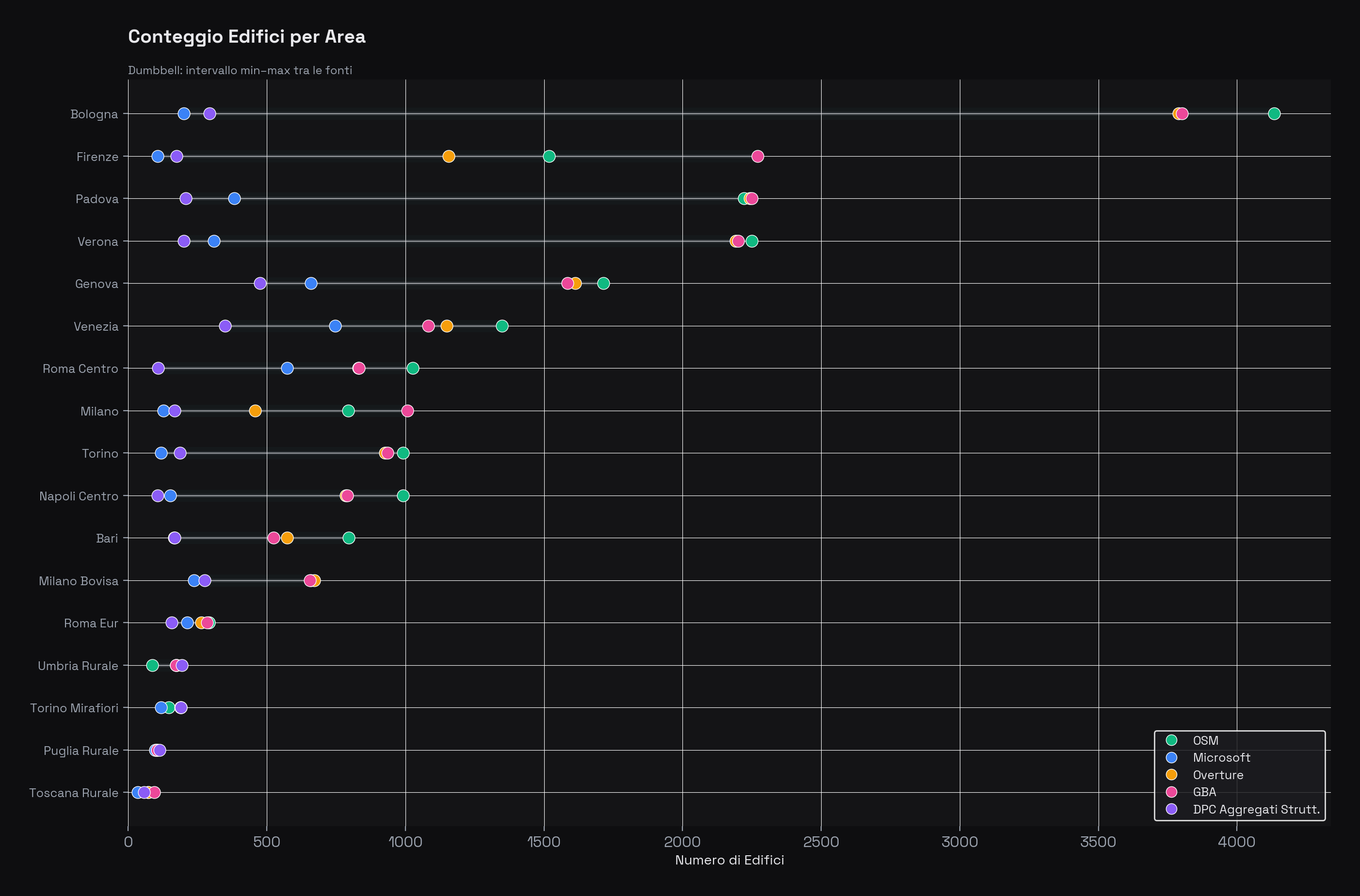
Conteggio edifici per area di studio: per ciascuna area la barra mostra l'intervallo fra la fonte più scarsa e la più ricca, con un punto per ciascun dataset. Si nota subito come OSM (teal) e Overture (azzurro) dominino quasi ovunque, mentre Microsoft (verde) e DPC (viola) abbiano conteggi sistematicamente più bassi.
Alcuni dati esemplificativi dalla nostra analisi:
- Bologna: OSM conta 4.134 edifici, Overture 3.790, GBA 3.802, Microsoft appena 200, DPC 293
- Venezia: OSM 1.349, Microsoft 746 (55% di OSM), DPC solo 349
- Puglia rurale: i conteggi convergono attorno a 100 per tutte le fonti — nelle aree con pochi edifici le differenze si riducono
- Firenze: caso peculiare dove GBA (2.271) supera OSM (1.519), suggerendo che la fusione accademica ha integrato edifici da Microsoft non presenti in OSM
Il dato Microsoft è coerentemente più basso perché il modello ML ha una soglia di confidenza, e molte strutture piccole nei centri storici italiani (portici coperti, tettoie, edifici contigui) vengono accorpate o ignorate. DPC registra numeri bassi per definizione, essendo composto da aggregati multi-edificio.
Come si distribuiscono le superfici?
Oltre al conteggio, è informativo confrontare la distribuzione delle aree delle impronte — una specie di "impronta digitale" del dataset.
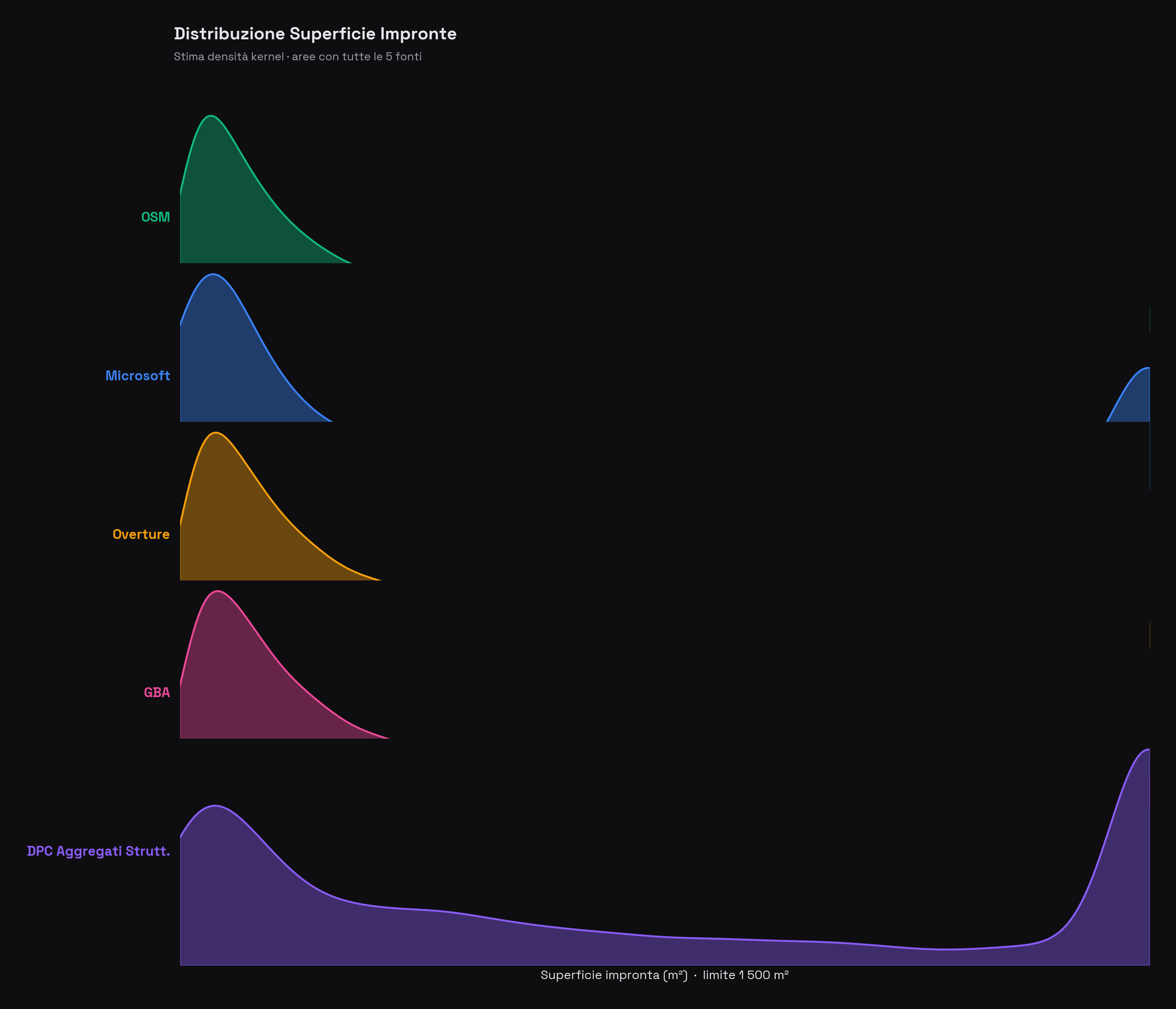
Distribuzione delle superfici delle impronte (stima kernel density). Ogni riga rappresenta una fonte. Il profilo di OSM e Overture è quasi sovrapponibile, a conferma della derivazione comune. Microsoft tende a produrre impronte leggermente più grandi (la curva è spostata a destra), per l'effetto di accorpamento tipico del machine learning.
Quanto sono accurate le impronte? Metriche di rilevamento a confronto
Passiamo al cuore dell'analisi: quanto bene ciascun dataset rileva gli stessi edifici presenti in OSM? Le tre metriche classiche della detection — precisione, richiamo e F1 — raccontano storie molto diverse.
Tabella riepilogativa delle metriche aggregate
| Dataset | Precisione | Richiamo | F1 | IoU Medio | Edifici abbinati |
|---|---|---|---|---|---|
| Overture | 0,908 | 0,882 | 0,880 | 0,990 | 21.096 |
| GBA | 0,845 | 0,866 | 0,843 | 0,979 | 16.695 |
| DPC | 0,585 | 0,254 | 0,290 | 0,667 | 2.449 |
| Microsoft | 0,461 | 0,230 | 0,263 | 0,556 | 2.450 |
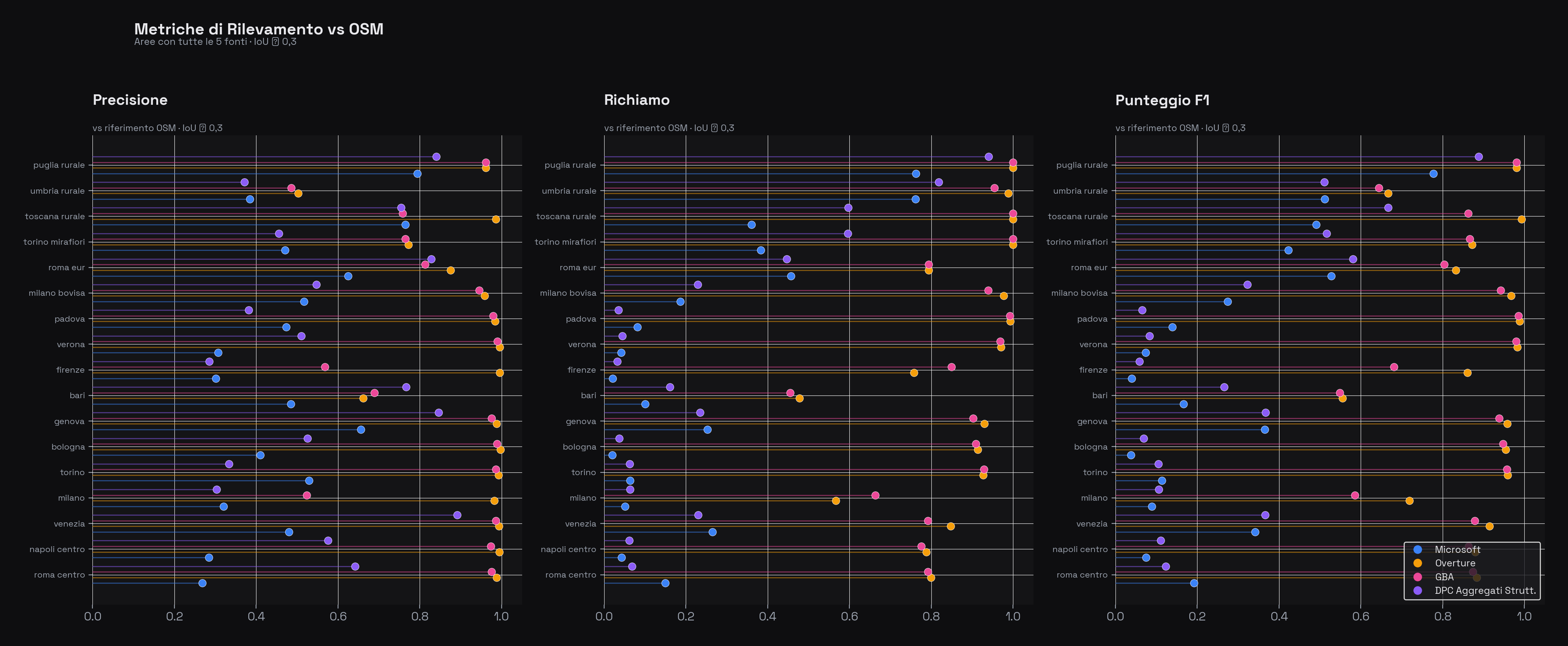
Metriche di rilevamento per area e per fonte (vs OSM, soglia IoU ≥ 0,3). Ogni punto rappresenta un'area di studio. Si noti come Overture e GBA formino un cluster compatto in alto a destra, mentre Microsoft e DPC mostrano maggiore dispersione e valori più bassi.
Come interpretare questi numeri?
Overture domina con F1 = 0,880, precisione 0,908 e 21.096 edifici abbinati. È il risultato atteso: Overture in Italia è sostanzialmente OSM rielaborato, quindi il matching con il riferimento OSM è quasi perfetto. L'IoU medio di 0,990 conferma che le geometrie sono quasi identiche.
GBA segue a ruota con F1 = 0,843 e 16.695 edifici abbinati. Ha meno match di Overture perché il filtraggio qualitativo rimuove alcune impronte incerte, ma quelle che restano hanno IoU = 0,979 — molto alto.
Microsoft sorprende con F1 = 0,263, un valore che potrebbe sembrare basso ma va letto nel contesto: le geometrie prodotte dal machine learning sono strutturalmente diverse da quelle OSM ricalcate dal catasto. Anche quando coprono lo stesso edificio, le forme differiscono abbastanza da far scendere l'IoU sotto la soglia di 0,3. Non significa che Microsoft sia "sbagliato" — significa che misura gli edifici in modo diverso. L'IoU medio dei match trovati è comunque 0,556.
DPC ha F1 = 0,290 per un motivo ancora più fondamentale: gli aggregati strutturali non sono singoli edifici. Un aggregato tipico copre 3-5 edifici contigui: l'IoU con qualsiasi singolo edificio OSM sarà per forza basso.
Distribuzione dell'IoU: quanto si sovrappongono le sagome?
Per capire meglio il profilo di accuratezza, è utile guardare non solo la media ma l'intera distribuzione dell'Intersection over Union degli edifici abbinati.
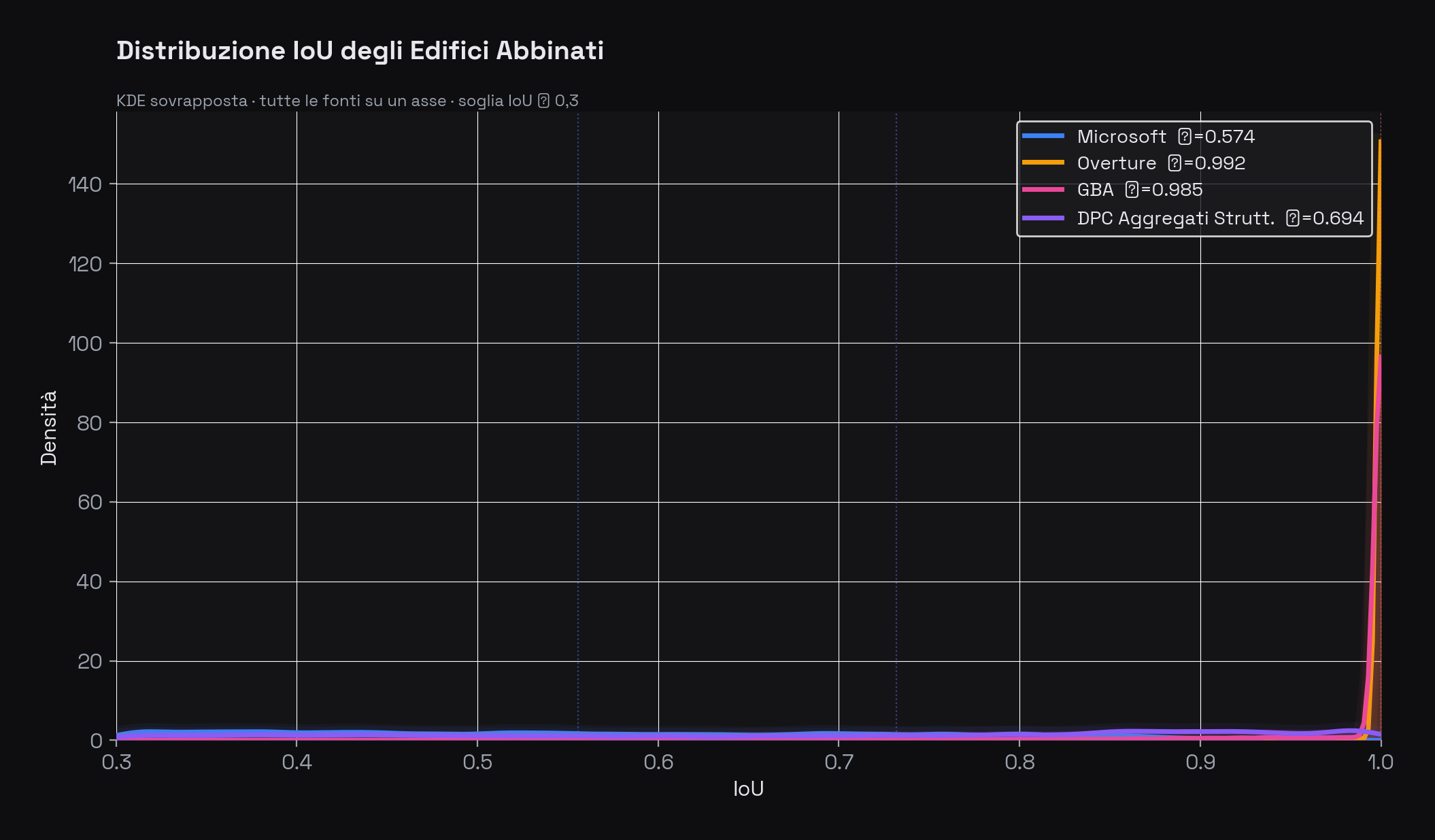
Distribuzione IoU dei building match. Il picco di Overture a IoU ≈ 1,0 conferma la quasi-identità geometrica con OSM. GBA ha un profilo simile, appena più disperso per l'effetto della fusione. Microsoft mostra una curva pressoché piatta centrata su 0,55 — le sue geometrie "combaciano" con OSM solo in modo approssimativo.
Quanto sono spostati i centroidi?
Lo spostamento del centroide misura la dislocazione posizionale media tra le impronte abbinate: un centroide spostato di 5 metri significa che il dataset colloca l'edificio 5 metri più in là rispetto a OSM.
| Fonte | Spostamento mediano | Spostamento medio |
|---|---|---|
| Overture | 0,00 m | 0,05 m |
| GBA | 0,00 m | 0,13 m |
| DPC | 2,02 m | 5,46 m |
| Microsoft | 3,80 m | 5,88 m |
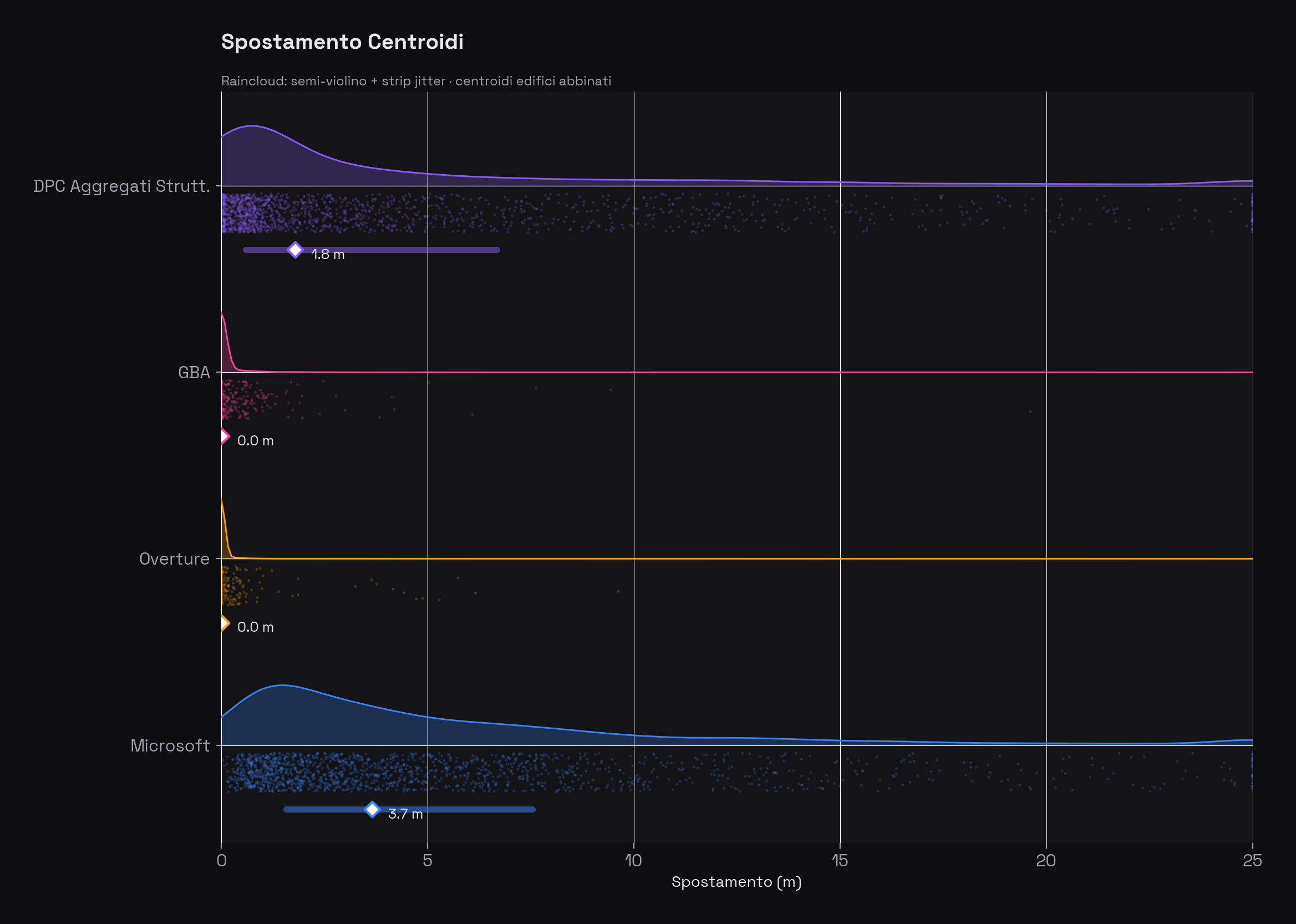
Spostamento dei centroidi rispetto a OSM (raincloud chart con semi-violino + strip jitter). Il diamante bianco indica la mediana, la barra colorata l'intervallo interquartile. Overture e GBA sono praticamente a spostamento 0 — le impronte coincidono con OSM. Microsoft ha una mediana di 3,80 m, coerente con l'accuratezza tipica delle immagini satellitari sub-metriche.
Distanza di Hausdorff: quanto differiscono le forme?
La distanza di Hausdorff misura la massima distanza tra i contorni di due impronte abbinate. Se il centroide indica dove è l'edificio, Hausdorff indica quanto è diversa la forma.
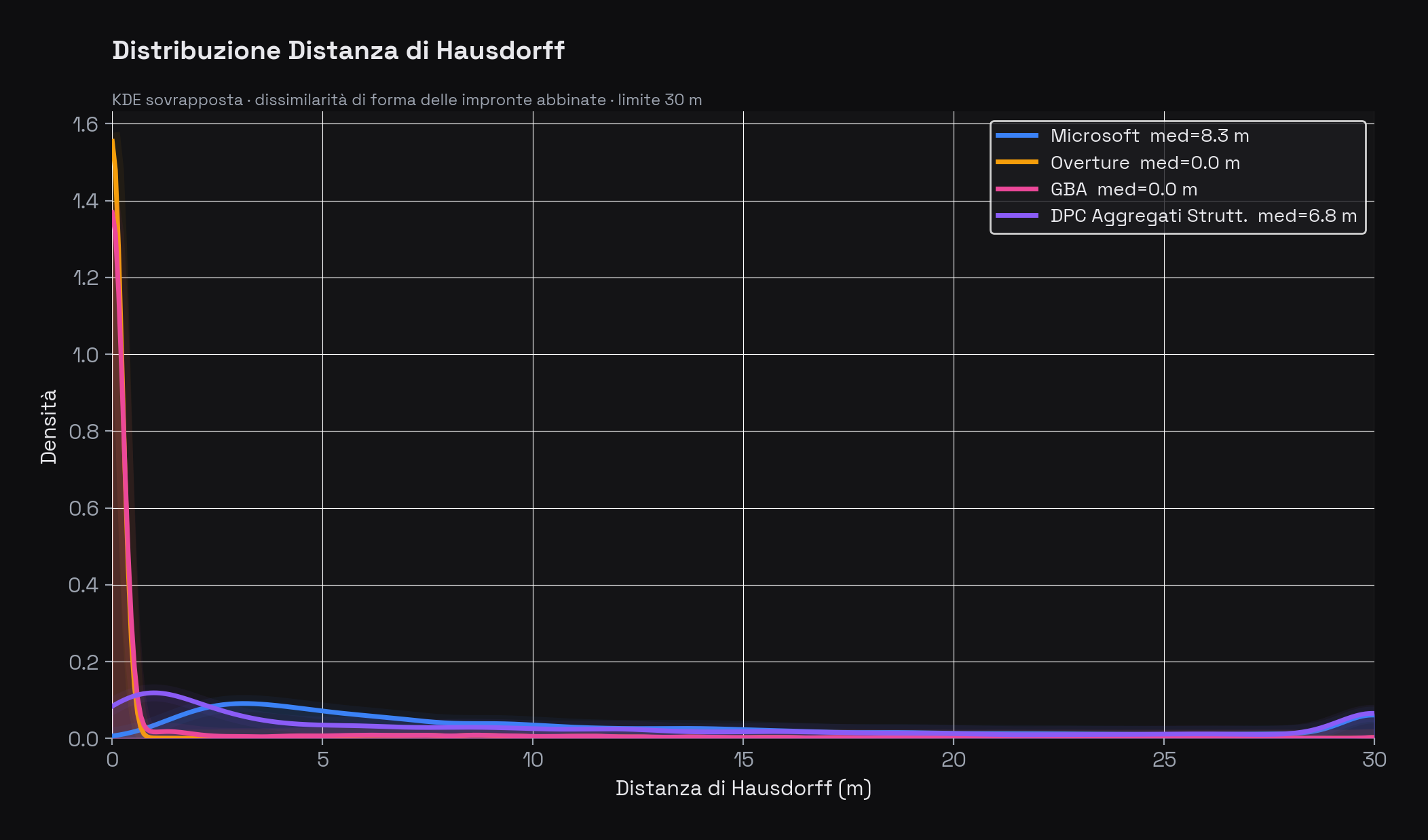
Distribuzione della distanza di Hausdorff (dissimilarità di forma). Mediana: Overture 0,00 m, GBA 0,00 m, DPC 7,92 m, Microsoft 8,41 m. I valori di Microsoft e DPC riflettono rispettivamente la semplificazione ML delle geometrie e la natura multi-edificio degli aggregati DPC.
Profilo qualitativo globale: il radar a 6 dimensioni
Per avere una visione d'insieme, abbiamo sintetizzato sei indicatori di qualità in un unico grafico radar: validità geometrica, compattezza (Miller), rettangolarità, precisione vs OSM, richiamo vs OSM e IoU medio.
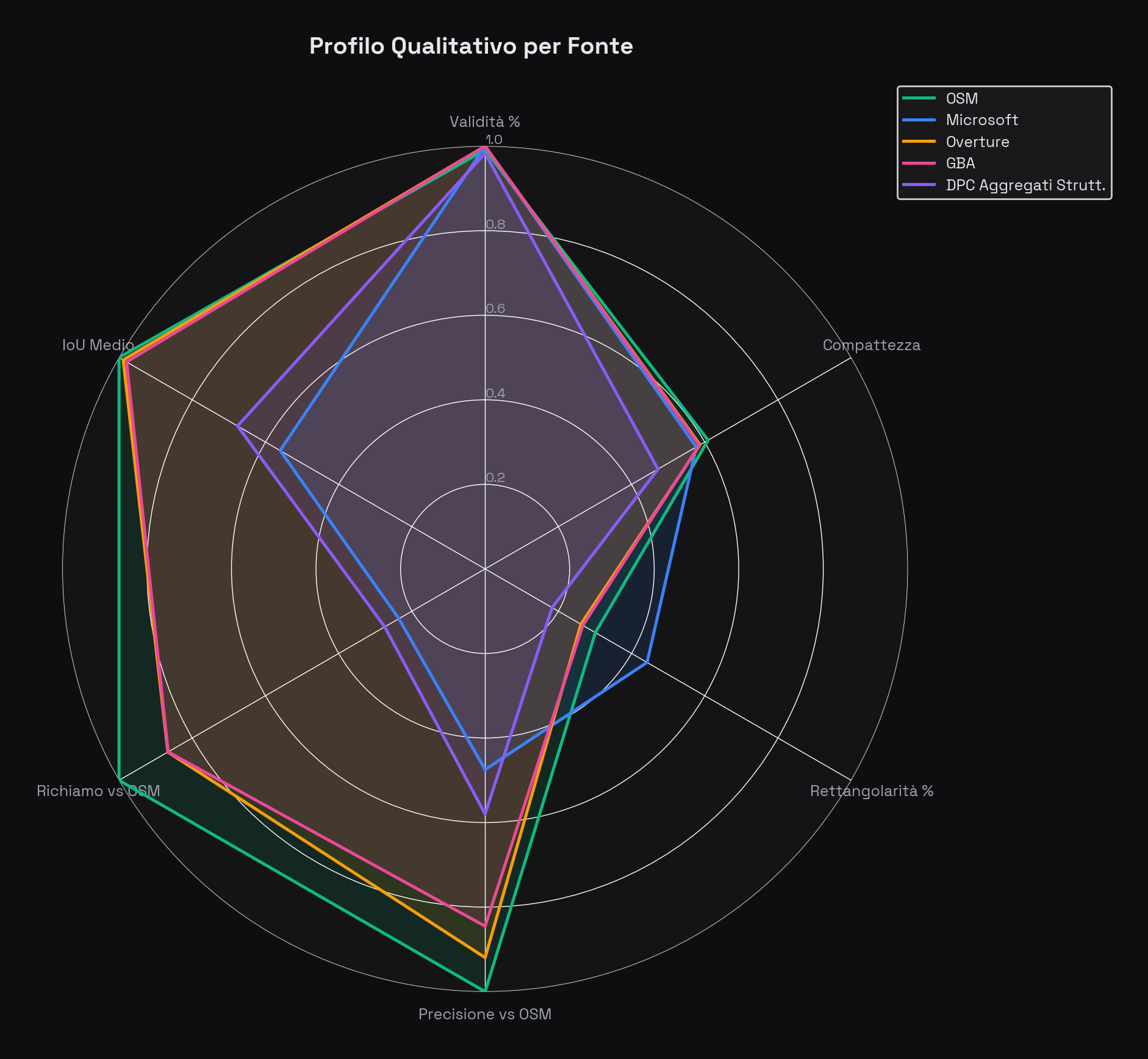
Profilo qualitativo per fonte. Overture e GBA hanno i poligoni più equilibrati — buone prestazioni su tutti gli assi. OSM eccelle in validità (99,3%) e ha il profilo semantico più ricco (non visualizzato qui). Microsoft brilla in compattezza geometrica ma sconta la diversità morfologica rispetto a OSM sugli assi di matching.
Qualità geometrica nel dettaglio
| Indicatore | OSM | Microsoft | Overture | GBA | DPC |
|---|---|---|---|---|---|
| Validità | 99,3% | 100% | 100% | 100% | 98,4% |
| Compattezza (Miller) | 0,618 | 0,582 | 0,593 | 0,589 | 0,472 |
| Rettangolarità | 30,9% | 45,5% | 27,6% | 27,2% | 20,2% |
| Vertici medi | 9,8 | 10,7 | 10,4 | 10,1 | 26,6 |
| Piccole impronte (<10 m²) | 3,0% | 1,8% | 2,0% | 2,2% | 5,0% |
| Auto-sovrapposizioni | 9,3% | 15,9% | 0,8% | 0,2% | 0,0% |
Da notare che Microsoft ha 0 geometrie invalide (le reti neurali producono poligoni puliti) ma il 15,9% di auto-sovrapposizioni — un problema noto del processo ML che crea impronte sovrapposte per edifici vicini. Overture e GBA, grazie ai processi di conflazione e filtraggio, hanno auto-sovrapposizioni quasi nulle (0,8% e 0,2%).
DPC spicca per i 26,6 vertici medi per impronta (il triplo delle altre fonti) e la compattezza più bassa (0,472), perché gli aggregati hanno forme irregolari che seguono il perimetro di più edifici contigui.
Cosa dicono i metadati? Non solo geometrie
Un dataset di buona qualità non è fatto solo di geometrie accurate: la ricchezza dei metadati (altezza, tipo, nome, numero di piani) è cruciale per molte applicazioni.
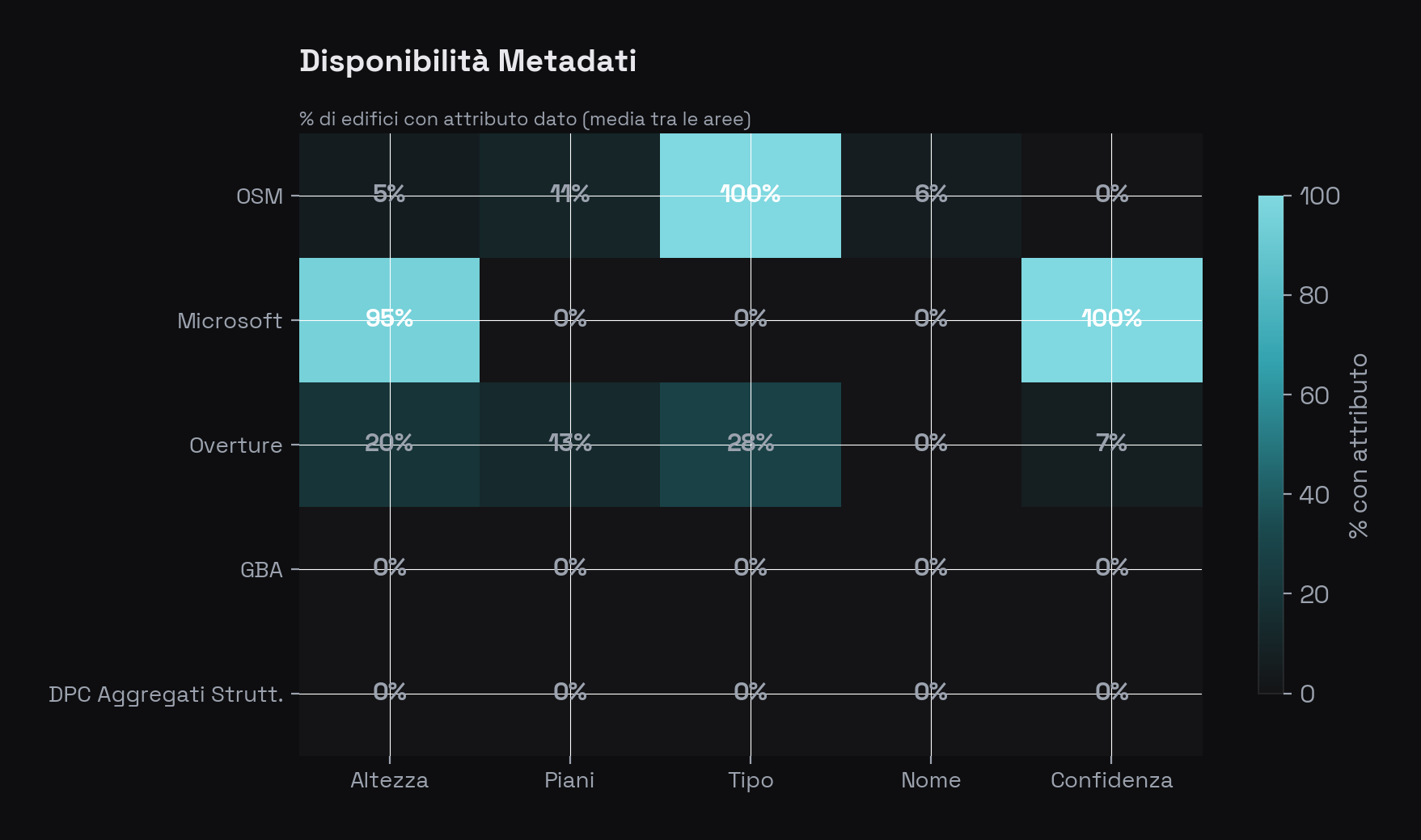
Disponibilità metadati per fonte. Ogni cella indica la percentuale media di edifici che ha l'attributo corrispondente. Microsoft è l'unica fonte con altezza stimata e punteggio di confidenza per il 100% degli edifici. OSM è l'unica con informazioni semantiche significative (tipo, nome, piani). Come spesso accade con i dati open data, le fonti sono complementari piuttosto che sostitutive.
Confronto visivo: le mappe parlano da sole
I grafici aggregati raccontano le tendenze, ma per capire davvero le differenze bisogna vedere le impronte sovrapposte alla mappa. Ecco due casi esemplificativi che rappresentano gli estremi del nostro campione.
Roma Centro: il tessuto storico denso

Confronto spaziale nel centro storico di Roma (1.027 edifici OSM). Emergono chiaramente le differenze: OSM e Overture catturano i singoli edifici con precisione catastale. Microsoft rileva le strutture maggiori ma perde i cortili interni e accorpa edifici contigui. DPC mostra i suoi caratteristici aggregati — poligoni che avvolgono interi isolati.
Toscana rurale: case sparse nella campagna
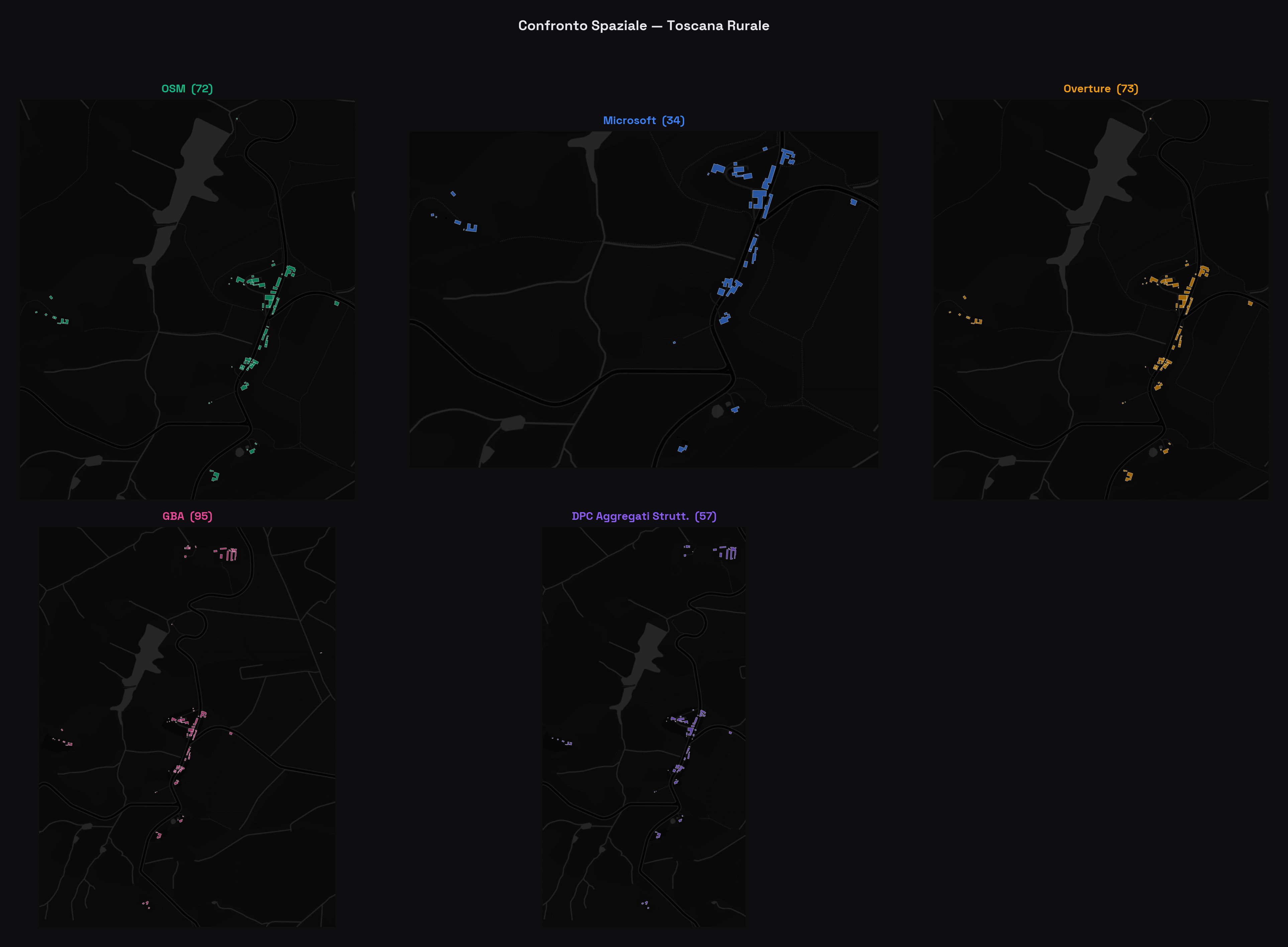
Confronto spaziale in un'area rurale toscana (72 edifici OSM). Nelle aree con pochi edifici isolati, la differenza principale è nella completezza: Microsoft rileva solo 34 strutture (47% di OSM), confermando che il suo modello ML ha una soglia di dimensione minima che penalizza le strutture rurali minori.
Milano e Firenze

Milano: grandi isolati regolari dove tutte le fonti convergono. La tipologia suburbana-moderna è la più semplice per i modelli ML.
Firenze: caso interessante dove GBA ha più impronte (2.271) di OSM (1.519), suggerendo che la fusione accademica ha integrato edifici Microsoft non presenti in OSM.
Robustezza dei risultati: sensibilità alla soglia IoU
La soglia IoU ≥ 0,3 che abbiamo usato è una convenzione della letteratura (Biljecki et al., 2021), ma non è una costante universale. Come cambiano i risultati se la spostiamo?
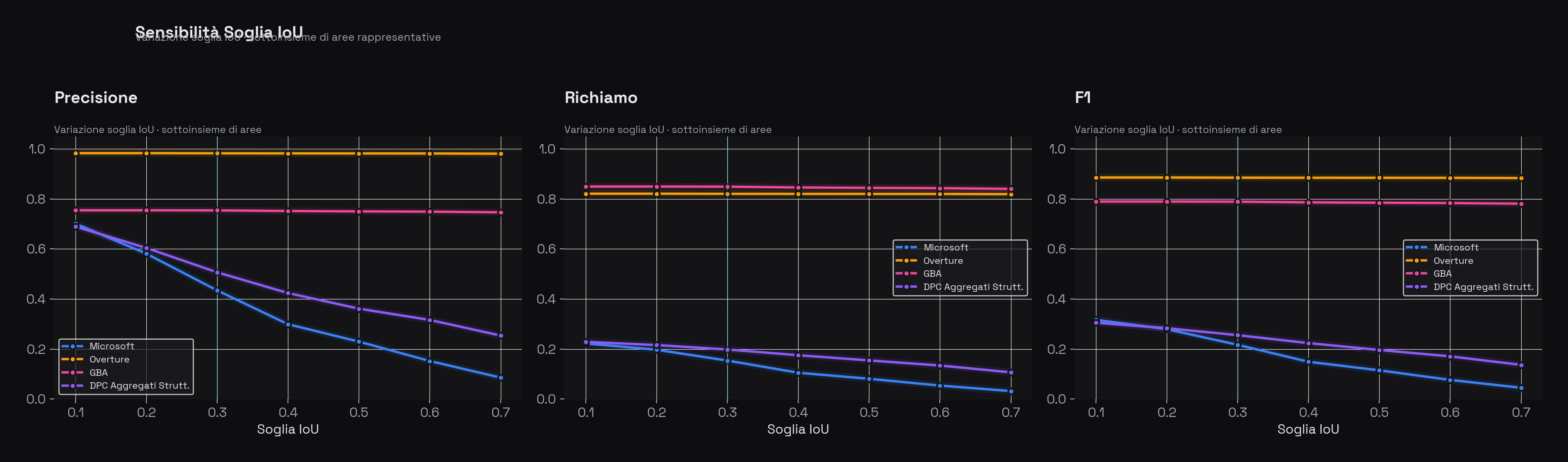
Sensibilità alla soglia IoU (variazione da 0,1 a 0,7). Overture e GBA sono robusti: il loro F1 scende da ~0,88 a ~0,82 passando da IoU=0,3 a IoU=0,5. Microsoft invece è molto sensibile: F1 cala da ~0,4 a ~0,1 nello stesso intervallo, confermando che le forme ML combaciano con OSM in modo strutturalmente diverso — non è solo una questione di "qualità".
F1 per tipologia urbana: dove funziona meglio ciascun dataset?
Non tutte le aree sono uguali. Il contesto urbano influenza pesantemente le prestazioni di ciascun dataset.
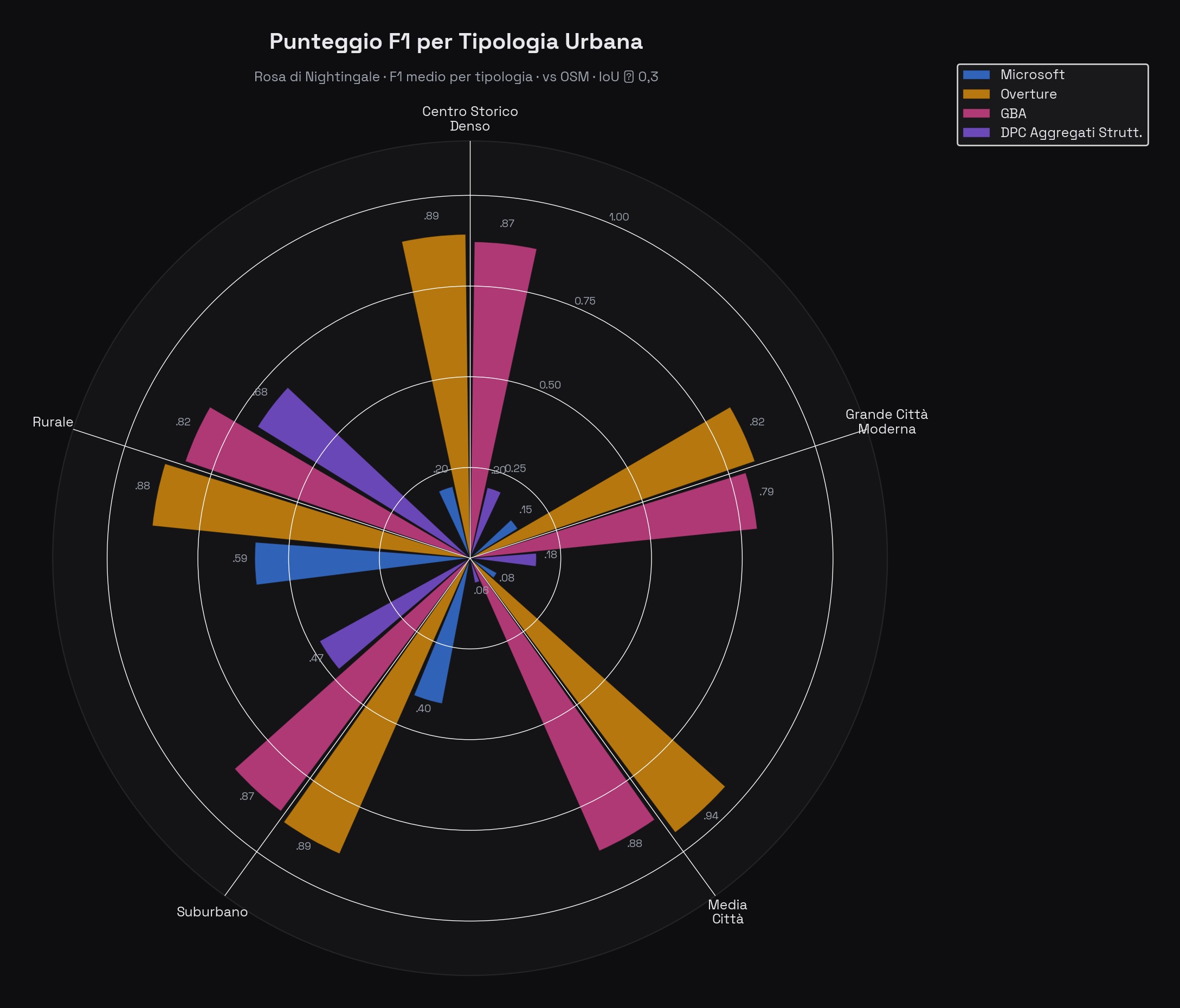
Punteggio F1 per tipologia urbana (rosa di Nightingale). I centri storici densi sono la sfida più difficile per tutti i dataset: geometrie irregolari, cortili interni, edifici contigui che i modelli ML faticano a distinguere. Le aree suburbane con edifici regolari e ben separati producono i risultati migliori per tutte le fonti.
Errori a confronto: chi sbaglia e come?
Capire dove e come un dataset sbaglia è spesso più informativo della metrica aggregata.
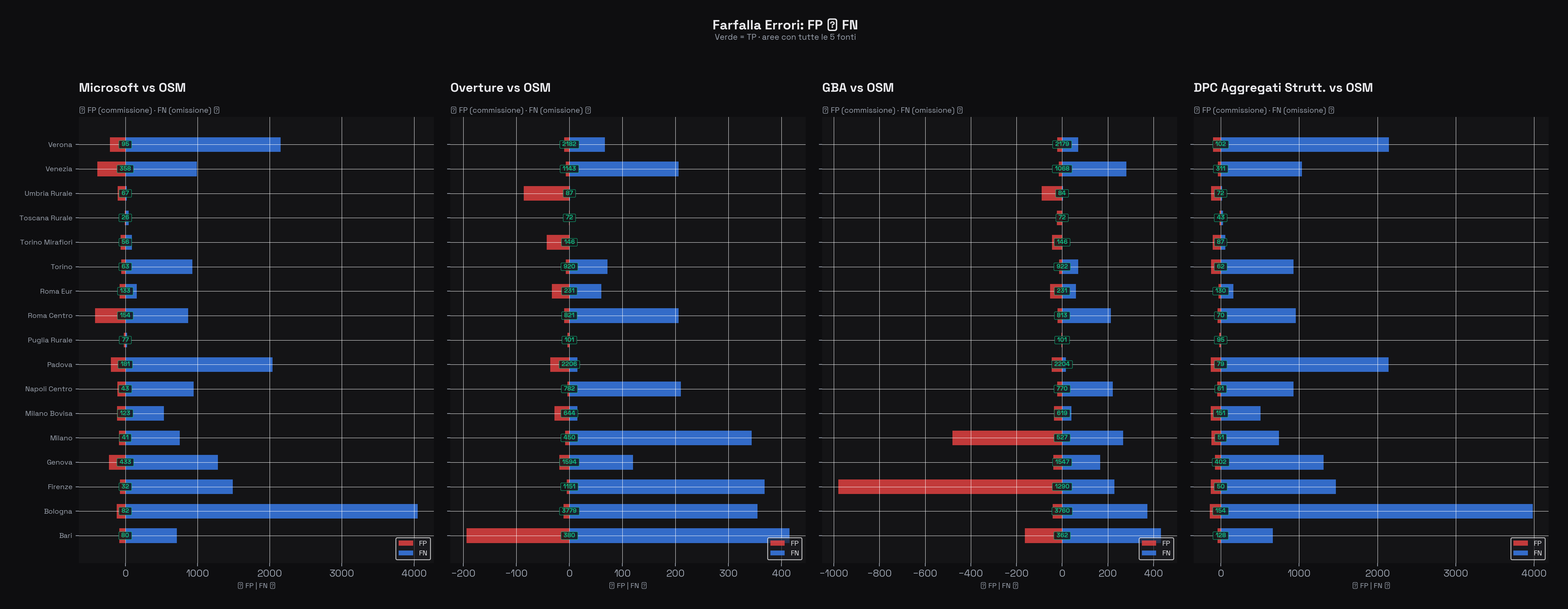
Distribuzione dei falsi positivi (FP, a sinistra) e falsi negativi (FN, a destra) per area e per fonte. In verde al centro: i True Positive. Overture e GBA hanno profili snelli e bilanciati. Microsoft ha molti FP (strutture rilevate dal ML che OSM non ha) e molti FN (edifici OSM che il modello non rileva) — ma attenzione: molti di quei "falsi positivi" Microsoft potrebbero essere edifici reali non ancora mappati in OSM.
Densità e copertura: il quadro d'insieme
Infine, uno sguardo alla relazione tra densità di edifici (quanti per km²) e copertura del suolo (percentuale della superficie coperta dalle impronte).
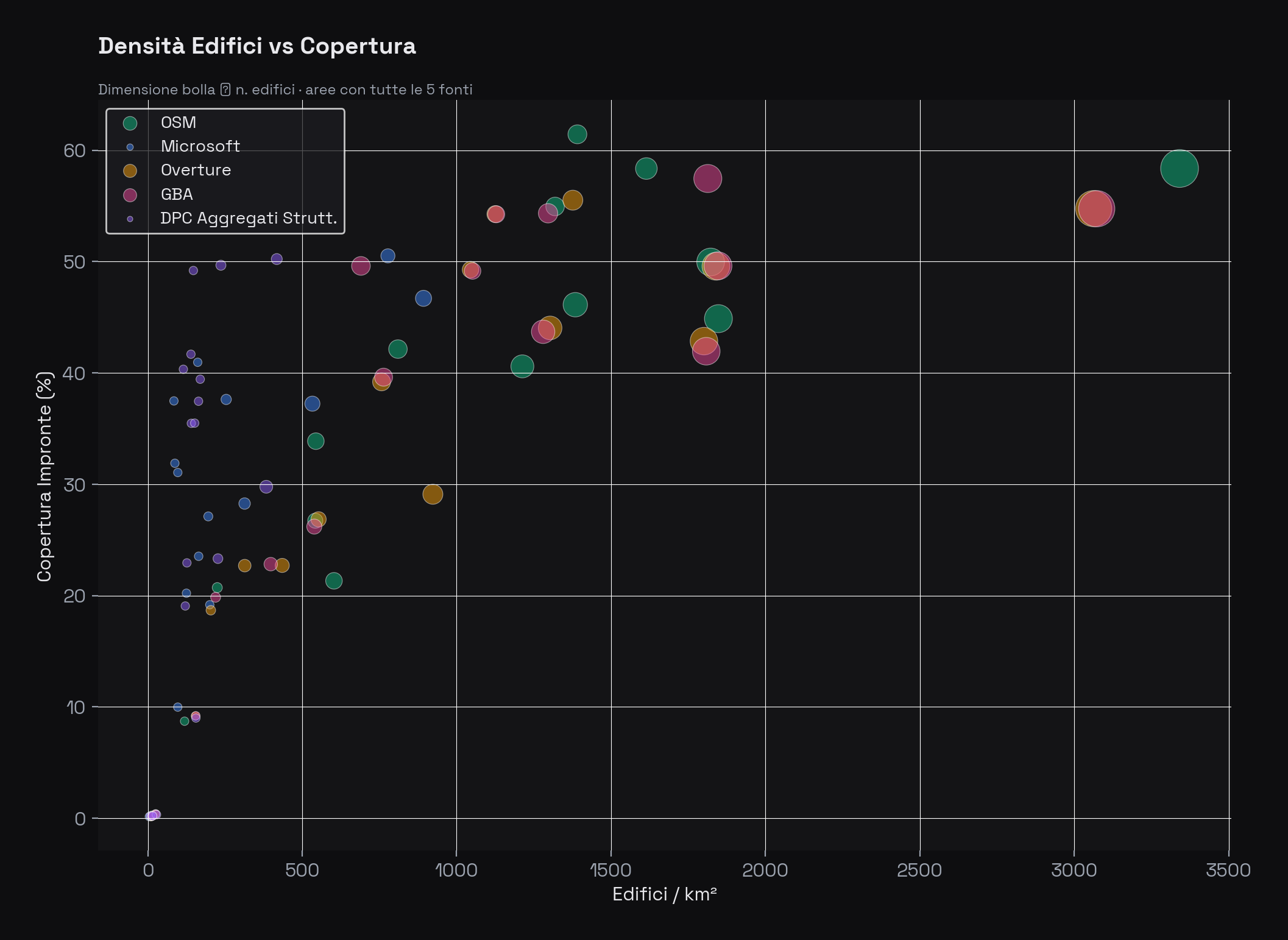
Densità vs copertura (bubble chart). Ogni bolla è un'area di studio, con dimensione proporzionale al conteggio degli edifici. Le aree urbane dense come Bologna (3.341 edifici/km² in OSM) e Venezia (1.614/km²) emergono in alto a destra. Le aree rurali si concentrano nell'angolo in basso a sinistra con densità sotto i 25 edifici/km².
Quale dataset scegliere? Guida pratica per caso d'uso
Dopo aver analizzato 18 indicatori su 22 aree, possiamo formulare raccomandazioni pratiche per i casi d'uso più comuni nel contesto italiano:
| Caso d'uso | Dataset consigliato | Motivazione |
|---|---|---|
| Analisi urbanistica dettagliata | OSM | Massima completezza e semantica (tipo, piani, nome). Ideale per pianificazione urbana e studi di dettaglio. |
| Copertura globale e altezze stimate | Microsoft | Coerenza globale, 100% con altezza stimata e punteggio di confidenza. Ideale per analisi su larga scala dove serve uniformità. |
| API e applicazioni con ID stabili | Overture | Schema normalizzato, ID persistenti, qualità equivalente a OSM in Italia. Ideale per applicazioni software e integrazioni. |
| Modellazione 3D e ricerca accademica | GBA | Fusione qualitativa con altezze LoD1 integrate. Meno dati grezzi, ma più puliti. Ideale per digital twin e CityGML. |
| Classificazione rischio sismico | DPC | Unica fonte per aggregati strutturali con codice IDAG. Indispensabile per la vulnerabilità sismica. |
| Massima copertura possibile | Fusione multi-fonte | Combinare OSM (completezza) + Microsoft (rilevamento ML) colma le lacune reciproche. Richiede un pipeline di conflazione. |
Limiti dell'analisi e note metodologiche
Questa analisi è la più completa che conosciamo per il contesto italiano, ma ha limiti importanti che vanno esplicitati:
OSM come riferimento non è perfetto: gli edifici reali non mappati in OSM risultano falsi positivi. Questo penalizza Microsoft in particolare, che rileva strutture dai satelliti che la comunità OSM non ha ancora mappato.
Disallineamento temporale: i dataset hanno epoche diverse — da DPC (~2020) a Overture (febbraio 2026). Edifici costruiti, demoliti o modificati nel frattempo alterano le metriche.
22 aree non sono l'Italia intera: il nostro campione copre le tipologie principali ma non ha validità statistica a livello comunale. Le aree montane alpine, le isole minori e i centri con meno di 10.000 abitanti sono sotto-rappresentati.
MAUP (Modifiable Areal Unit Problem): spostare il bounding-box di anche 50 metri può cambiare i conteggi del 5-15% nelle aree dense.
DPC non è confrontabile 1:1: gli aggregati strutturali non sono singoli edifici — il matching produce metriche strutturalmente basse per ragioni ontologiche, non di qualità.
Riproducibilità
L'intera analisi è condotta con Python (GeoPandas, Shapely, Matplotlib, SciPy) ed è completamente riproducibile. Il pipeline comprende:
- Script di download automatico per tutte e 5 le fonti (Overpass API, Microsoft Planetary Computer, Overture S3, GBA tile server, DPC GitHub)
- Pre-elaborazione con esclusione bordo, validazione geometrica e riproiezione UTM
- Matching greedy con cache per evitare ricalcoli
- 14 tipologie di grafici con estetica neumorphism coerente
- Report testuale automatico con tutte le statistiche numeriche
Il codice sorgente, i dati campione e gli script sono disponibili su richiesta.